Top 30 Free Web Scraping Software In 2020 
Content
Making Web Data Extraction
Beauty Products & Cosmetics Shops Email List and B2B Marketing Listhttps://t.co/EvfYHo4yj2
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Our Beauty Industry Marketing List currently contains in excess of 300,000 business records. pic.twitter.com/X8F4RJOt4M
You also can see that if you interact with the web site, the URL in your browser’s tackle bar additionally changes. The first step is to move over to the positioning you wish to scrape utilizing your favourite browser. You’ll need to know the positioning construction to extract the knowledge you’re thinking about. However, understand that because the internet is dynamic, the scrapers you’ll construct will in all probability require fixed maintenance. You can set up steady integration to run scraping tests periodically to ensure that your main script doesn’t break with out your data. 
Jewelry Stores Email List and Jewelry Contacts Directoryhttps://t.co/uOs2Hu2vWd
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Our Jewelry Stores Email List consists of contact details for virtually every jewellery store across all states in USA, UK, Europe, Australia, Middle East and Asia. pic.twitter.com/whSmsR6yaX
Easy And Accessible For Everyone
 If you check out the downloaded content, then you’ll notice that it appears similar to the HTML you have been inspecting earlier with developer tools. To enhance the construction of how the HTML is displayed in your console output, you can print the thing’s .content attribute with pprint(). You can see that there’s an inventory of jobs returned on the left aspect, and there are extra detailed descriptions concerning the chosen job on the right side. When you click on on any of the jobs on the left, the content on the right adjustments.
If you check out the downloaded content, then you’ll notice that it appears similar to the HTML you have been inspecting earlier with developer tools. To enhance the construction of how the HTML is displayed in your console output, you can print the thing’s .content attribute with pprint(). You can see that there’s an inventory of jobs returned on the left aspect, and there are extra detailed descriptions concerning the chosen job on the right side. When you click on on any of the jobs on the left, the content on the right adjustments.
Extract Data From Dynamic
Import.io makes use of chopping-edge technology to fetch tens of millions of information every day, which companies can avail for small fees. Along with the online tool, it also presents a free apps for Windows, Mac OS X and Linux to construct information extractors and crawlers, obtain data and sync with the web account. Import.io provides a builder to kind your personal datasets by merely importing the information from a selected web page and exporting the info to CSV.
Web Sites
This will look fully different from what you noticed if you inspected the web page with your browser’s developer tools. That means you’ll want an account to be able to see (and scrape) something from the page. The process to make an HTTP request out of your Python script is completely Lead Generation Software for B2Bs different than how you access a web page from your browser. That signifies that simply because you'll be able to log in to the web page through your browser, that doesn’t imply you’ll be able to scrape it together with your Python script.
Exercising and Running Outside during Covid-19 (Coronavirus) Lockdown with CBD Oil Tinctures https://t.co/ZcOGpdHQa0 @JustCbd pic.twitter.com/emZMsrbrCk
— Creative Bear Tech (@CreativeBearTec) May 14, 2020
A internet scraper reverses this course of by taking unstructured sites and turning them again into an organized database. This data can then be exported to a database or a spreadsheet file, such as CSV or Excel.
Formats
- Web knowledge extraction consists of however not restricted to social media, e-commerce, advertising, actual estate itemizing and many others.
- Unlike other internet scrapers that only scrape content with simple HTML construction, Octoparse can deal with both static and dynamic web sites with AJAX, JavaScript, cookies and and so on.
- You can create a scraping task to extract information from a complex website similar to a website that requires login and pagination.
The website you’re scraping in this tutorial serves static HTML content. In this state of affairs, the server that hosts the site sends back HTML paperwork that already contain all the data you’ll get to see as a person.
JustCBD CBD Gummies - CBD Gummy Bears https://t.co/9pcBX0WXfo @JustCbd pic.twitter.com/7jPEiCqlXz
— Creative Bear Tech (@CreativeBearTec) April 27, 2020
You also can apply any other familiar Python string strategies to additional clean up your text. When you add the 2 highlighted lines of code, you’re creating a Beautiful Soup object that takes the HTML content you scraped earlier as its input. When you instantiate the item, you also instruct Beautiful Soup to use the suitable parser. It’s time to parse this prolonged code response with Beautiful Soup to make it more accessible and pick out the data that you’re thinking about. You won’t go deeper into scraping dynamically-generated content material in this tutorial. There’s a lot info on the Web, and new info is continually added. Something amongst all that information is likely of interest to you, and much of it is just out there for the taking. Do share your story with us utilizing the feedback part beneath. This is a realistic scenario, as many websites are in lively growth. Once the location’s structure has changed, your scraper might not be capable of navigate the sitemap appropriately or find the related info. The excellent news is that many modifications to websites are small and incremental, so you’ll likely be able to replace your scraper with solely minimal changes. For now, it’s enough so that you can remember that you’ll must look into the above-mentioned options if the web page you’re thinking about is generated in your browser dynamically. When you utilize requests, you’ll solely obtain what the server sends again. In the case of a dynamic web site, you’ll end up with some JavaScript code, which you received’t have the ability to parse utilizing Beautiful Soup. The only method to go from the JavaScript code to the content you’re thinking about is to execute the code, identical to your browser does. You’ve efficiently scraped some HTML from the Internet, however if you look at it now, it simply looks as if an enormous mess. There are tons of HTML elements here and there, thousands of attributes scattered round—and wasn’t there some JavaScript mixed in as nicely?  However, there are a number of more challenging situations you might encounter when you’re scraping websites. Before you start using Beautiful Soup to select the related information from the HTML that you just simply scraped, take a quick have a look at two of those conditions. You can simply scrape 1000's of net pages in minutes with out writing a single line of code and build 1000+ APIs based on your necessities. Web scraping tools can help hold you abreast on where your company or industry is heading within the next six months, serving as a robust software for market analysis. The tools can fetchd ata from multiple data analytics providers and market analysis companies, and consolidating them into one spot for simple reference and evaluation. Websites that show lists of knowledge usually do it by querying a database and displaying the data in a consumer friendly method. Scrapinghub is a cloud-primarily based data extraction device that helps 1000's of builders to fetch useful knowledge. Scrapinghub uses Crawlera, a smart proxy rotator that supports bypassing bot counter-measures to crawl large or bot-protected websites easily.
However, there are a number of more challenging situations you might encounter when you’re scraping websites. Before you start using Beautiful Soup to select the related information from the HTML that you just simply scraped, take a quick have a look at two of those conditions. You can simply scrape 1000's of net pages in minutes with out writing a single line of code and build 1000+ APIs based on your necessities. Web scraping tools can help hold you abreast on where your company or industry is heading within the next six months, serving as a robust software for market analysis. The tools can fetchd ata from multiple data analytics providers and market analysis companies, and consolidating them into one spot for simple reference and evaluation. Websites that show lists of knowledge usually do it by querying a database and displaying the data in a consumer friendly method. Scrapinghub is a cloud-primarily based data extraction device that helps 1000's of builders to fetch useful knowledge. Scrapinghub uses Crawlera, a smart proxy rotator that supports bypassing bot counter-measures to crawl large or bot-protected websites easily.
The requests library can’t try this for you, but there are other options that can. On the opposite hand, with a dynamic web site the server won't send back any HTML in any respect. 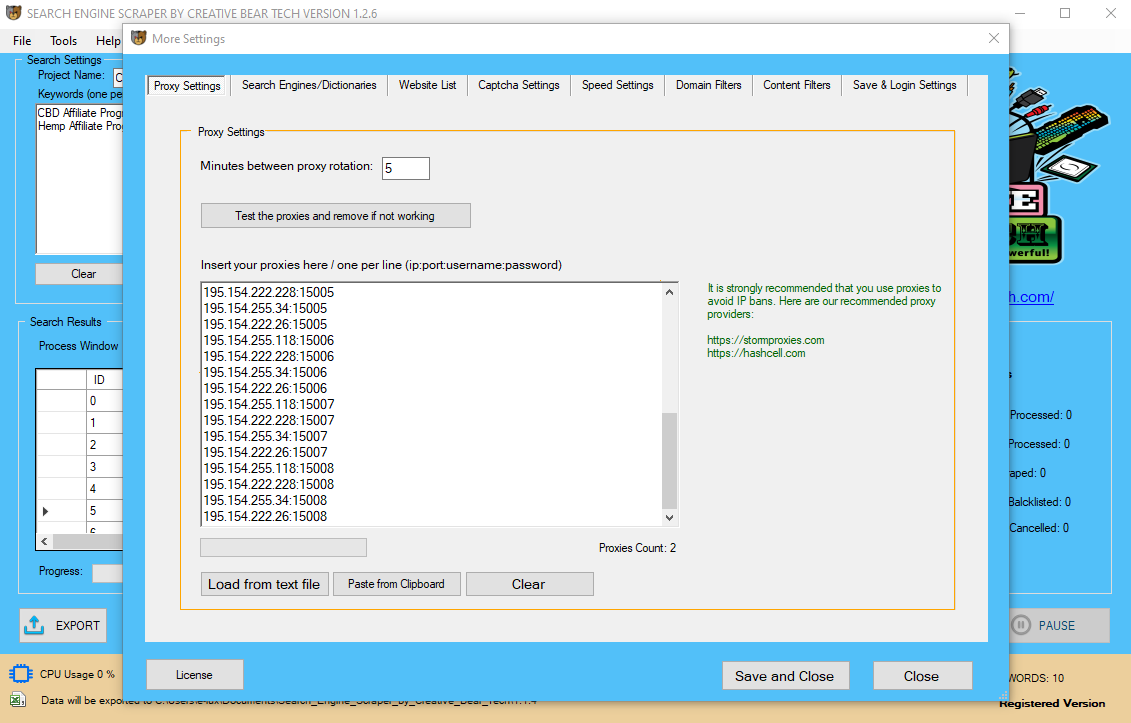
JustCBD CBD Bath Bombs & Hemp Soap - CBD SkinCare and Beauty @JustCbd https://t.co/UvK0e9O2c9 pic.twitter.com/P9WBRC30P6
— Creative Bear Tech (@CreativeBearTec) April 27, 2020